
百川智能的Baichuan 2-7B-Base和Baichuan 2-13B-Base是基于2.6万亿条高质量多语言数据进行训练的,它们在保留了上一代开源模型的出色生成与创作能力、流畅的多轮对话能力以及易用性等多个特点的基础上,还在数学、编码、安全、逻辑推理和语义理解等方面实现了显著的提升。特别是Baichuan 2-13B-Base,相比上一代的13B模型,数学能力提高了49%,编码能力提高了46%,安全能力提高了37%,逻辑推理能力提高了25%,语义理解能力提高了15%。 这两个模型在各种主要评估指标上表现出色,在MMLU、CMMLU、GSM8K等多个权威评估基准中,它们凭借绝对优势领先于LLaMA2,与其他相同参数规模的大型模型相比,表现也非常突出,性能明显超越了LLaMA2等竞争对手。 更值得一提的是,根据MMLU等多个权威英文评估基准的评分,Baichuan2-7B在英文主流任务上表现与130亿参数的LLaMA2持平。王小川表示,对于Baichuan2-7B和Baichuan2-13B,不仅对学术研究完全开放,开发者们只需通过邮件申请官方商用许可即可免费商用。 大型模型的训练过程包括获取大规模高质量数据、稳定的训练集群、模型算法优化等多个环节。每个环节都需要大量的人力和算力资源,从零开始训练一个模型成本极高,这阻碍了学术界对大型模型训练的深入研究。 因此,百川智能以协作和不断改进的态度,开源了模型训练从220B到2640B的完整Check Point。这对于科研机构来说是极具价值的资源,可以帮助他们研究大型模型的训练过程、持续训练和模型的价值观对齐等问题,将极大地推动国内大型模型的科研进展,开源训练模型过程在国内开源生态领域具有重要意义。 目前,大部分开源模型在公开过程中仅公开自身的模型权重,很少涉及训练细节。企业、研究机构和开发者只能在现有开源模型的基础上进行有限的微调,很难进行深入研究。 百川智能秉持更加开放和透明的理念,为了帮助从业者更深入地了解Baichuan 2的训练过程和相关经验,更好地推动大型模型社区的技术发展,宣布公开Baichuan 2的技术报告。这份技术报告将详细介绍Baichuan 2的全过程,包括数据处理、模型结构优化、Scaling law、过程指标等方面的内容。 百川智能自公司成立之初就一直致力于通过开源方式促进中国大型模型生态的繁荣。不到四个月的时间里,他们相继发布了Baichuan-7B、Baichuan-13B两款免费开源的中文大型模型,以及一款搜索增强大型模型Baichuan-53B。这两款开源模型在多个权威评估榜单上表现出色,目前已经被下载了超过500万次。 值得一提的是,在今年成立的大型模型公司中,百川智能是唯一一家根据《生成式人工智能服务管理暂行办法》备案的公司,正式向公众提供服务。凭借领先业界的基础大型模型研发和创新能力,他们的两款Baichuan 2大型模型得到了上下游企业的积极响应,腾讯云、阿里云、火山方舟、华为、联发科等众多知名企业都参与了本次发布会并与百川智能达成了合作协议。 未来,百川智能将继续深耕开源大型模型领域,分享更多技术能力和前沿创新,与更多合作伙伴一起助力中国大型模型生态的繁荣发展。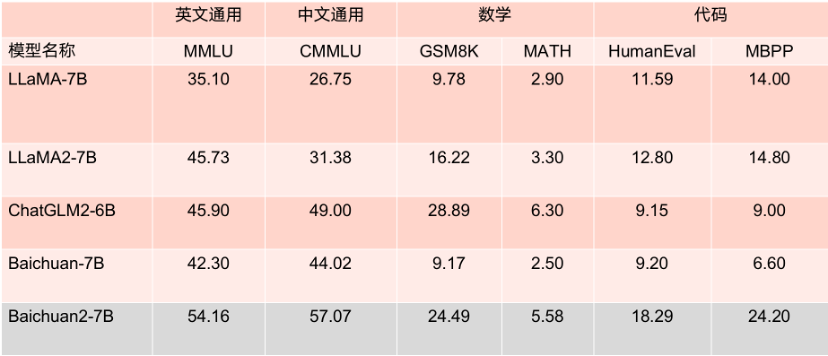

国内首次全程开源模型训练Check Point,助力学术研究

